Hello, I’m
Colm Sam |
Leveraging a background in particle physics and machine learning from projects at CERN and the LHC, I am now focused on using data and AI to build cool things.

Recent Projects
1) Notes2Flash
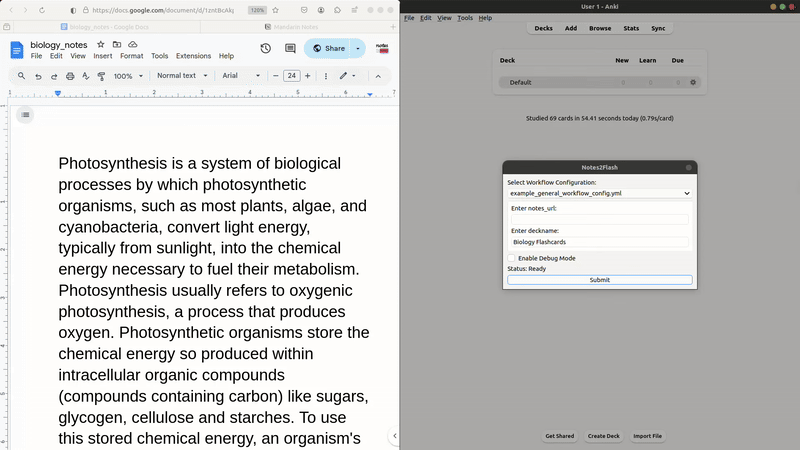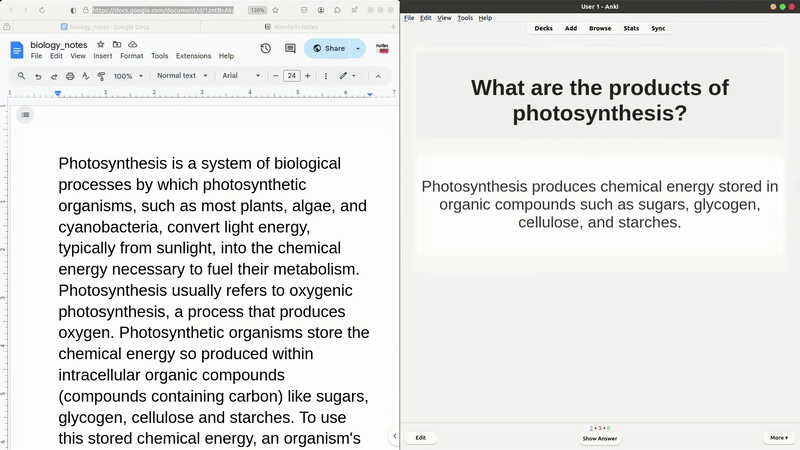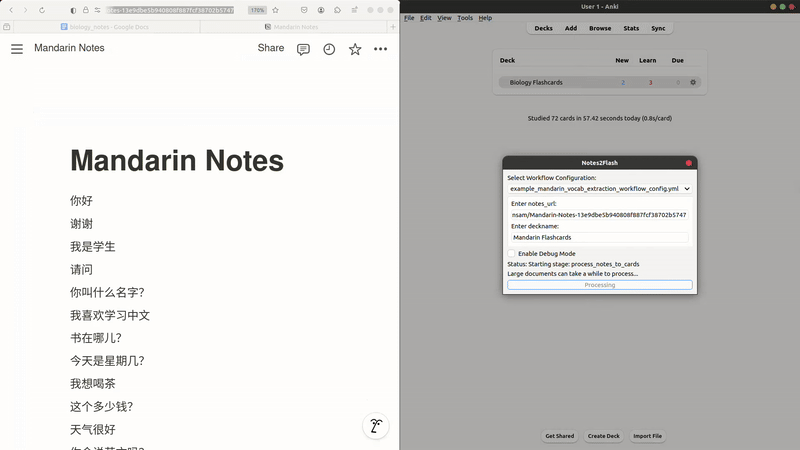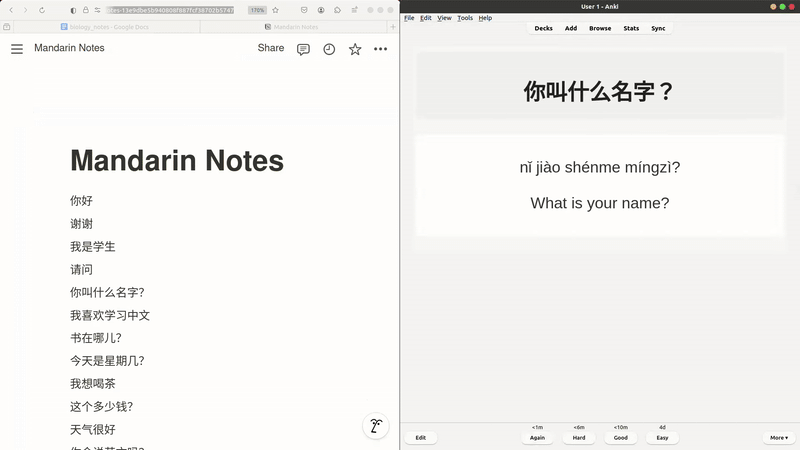
While living in Taiwan and learning Mandarin, I constantly encountered new words, phrases, and grammar that were unfamiliar to me. To remember them while on the go, I would jot them down in a Google Doc, with the overly optimistic idea that I’d later organize these notes into Anki flashcards. That Google Doc has since grown to over 60 pages, and I’ve yet to manually create a single flashcard, which led to Notes2Flash. With just a click of a button, I can now retrieve new content from my Google Docs—while tracking any changes—group and process it intelligently, and turn it into flashcards. Notes2Flash also supports notes written in Notion and Obsidian. It’s built with a focus on user flexibility, allowing users to customize their workflows by choosing from a range of LLMs (e.g., ChatGPT, Llama, Gemini), adding additional user inputs, and even chaining prompts together for more advanced workflows.
Tech stack: Python, LLMs, APIs
2) Xue-Xinwen.com
One of my favorite ways to procrastinate is by reading the news, so I decided to combine that with my passion for learning Mandarin. However, news websites for native speakers can be quite tricky for learners, with a more formal writing style and lots of niche, topic-specific words that non-natives struggle to understand. That’s why I developed Xue-Xinwen.com (where “Xue” means “to learn” and “xinwen” means “news”). It uses news-scraping APIs and NLP-driven language simplification to create a news website tailored for Mandarin learners.
Tech stack: OpenAI API (NLP), AWS (cloud computing), SQL + Flask (backend), React.js (frontend), Docker (containerization)
3) Cine Critic Pal - A letterboxd Sentiment Analysis
I have a friend who’s a film major and obsessed with documenting films on Letterboxd, but he refuses to assign star ratings to his reviews because, according to him, it’s too hard and causes him to overthink. This inspired me to build CineCriticPal, a machine learning model that assigns a rating based on a written review. The first step was building a dataset by using Selenium to scrape 100,000+ movie reviews and metadata from Letterboxd, like popularity, genre, and release date. After that, I fine-tuned a pre-trained large model (LLM) to predict movie ratings from 0.5 to 5 stars based on both the review and the metadata.
Tech stack: Selenium, Playwright (web scraping), sklearn, NLTK, Hugging Face, PyTorch (model training), Docker (containerization)
4) Distraction Deflector
As mentioned with Xue-Xinwen.com, I tend to procrastinate by reading the news. And while staying informed is great, it sometimes distracts me from more pressing tasks. Enter Distraction Deflector, a productivity browser extension that helps users stay focused by redirecting them away from distracting websites (like news sites) and toward things they need to get done—such as reading news on Xue-Xinwen.com, which yes is also a news site but conveniently doubles as language practice too.
Tech stack: React, JavaScript, HTML, CSS